A Look into GPT-Vision's Image Analysis Capabilities
The integration of artificial intelligence into our daily lives has become increasingly prevalent, and MobileGPT stands at the forefront of this revolution. With its powerful combination of GPT-4, SDXL, and GPT-4 Vision, MobileGPT offers a personalized AI experience like no other, directly on your favourite messaging platform, WhatsApp.
In this article, we'll delve into how GPT-Vision is revolutionizing the way we interact with images on our smartphones. From identifying objects and scenes to providing detailed descriptions and even generating creative interpretations, GPT-Vision opens up a world of possibilities for image analysis and understanding.

Below are the key points we'll be covering:
- Understanding GPT-Vision
- Demo: Experience firsthand the power of GPT-Vision
- Tips for Using GPT Vision to the Fullest
- Usecases for Image Analysis with GPT-4 Vision on MobileGPT
- Advantages of MobileGPT and GPT-Vision Integration
Join us on this journey as we uncover the incredible potential of GPT-Vision and glimpse into the future of mobile AI. Let's dive in and witness firsthand the transformative power of AI at our fingertips.
Understanding GPT-Vision: Exploring Image Analysis Capabilities
GPT-Vision is an advanced neural network model developed by OpenAI, designed specifically for image analysis tasks. It utilizes cutting-edge techniques in deep learning and computer vision to interpret and understand visual information with remarkable accuracy and efficiency. Let's delve deeper into its capabilities and significance in the realm of mobile AI:
What is GPT-Vision and How Does it Work?

GPT-Vision operates on a similar principle to its text-based counterpart, GPT, but with a focus on images. GPT-Vision represents a groundbreaking advancement in the field of computer vision, developed by OpenAI as an extension of their renowned GPT (Generative Pre-trained Transformer) architecture. Unlike traditional computer vision models that rely primarily on handcrafted features and complex algorithms, GPT-Vision leverages the power of deep learning and neural networks to automatically learn and understand visual content.
At its core, GPT-Vision operates on a transformer architecture, which is a type of neural network architecture known for its ability to handle sequential data with remarkable efficiency and scalability. Through a process known as self-attention, GPT-Vision can capture long-range dependencies within images, enabling it to effectively analyze and interpret visual content in a holistic manner.
The training process for GPT-Vision involves exposing the model to vast amounts of labeled image data, allowing it to learn patterns, features, and relationships within visual content. By learning from examples, GPT-Vision can develop a rich understanding of various concepts, objects, and scenes present in images, enabling it to generate accurate and contextually relevant responses.
Once trained, GPT-Vision can perform a wide range of image analysis tasks, including but not limited to:
- Object Recognition: Identifying and localizing objects within images, regardless of their position, scale, or orientation.
- Scene Understanding: Inferring the context and semantics of scenes depicted in images, such as indoor versus outdoor environments, urban versus rural landscapes, etc.
- Image Captioning: Generating descriptive captions or summaries for images, providing human-like interpretations of visual content.
- Visual Question Answering: Responding to questions posed about images, providing relevant and accurate answers based on the visual context.
GPT-Vision represents a significant advancement in the field of computer vision, offering a versatile and powerful tool for understanding and interpreting visual content with human-like accuracy and intelligence. Its integration into platforms like MobileGPT opens up a world of possibilities for mobile AI, enabling users to seamlessly interact with and harness the power of advanced image analysis capabilities on their smartphones and other mobile devices.
The significance of GPT-Vision in mobile AI lies in its ability to bring sophisticated image analysis capabilities directly to smartphones and other mobile devices. This means users can harness the power of AI for tasks like object recognition, image captioning, and visual search, all from the palm of their hand.
GPT-4 Vision's Capabilities and Advancements

As the latest iteration of GPT-Vision, GPT-4 Vision represents a significant leap forward in the capabilities and performance of AI-driven image analysis. Built upon the foundation laid by its predecessors, GPT-4 Vision boasts several advancements that push the boundaries of what is possible in computer vision.
Enhanced Training Techniques: GPT-4 Vision benefits from improved training techniques, allowing it to learn from larger and more diverse datasets. By exposing the model to a wide range of labeled images, GPT-4 Vision can develop a deeper understanding of visual concepts and nuances, resulting in more accurate and robust image analysis.
Advanced Neural Architectures: GPT-4 Vision incorporates state-of-the-art neural architectures, including transformer-based models, that enable it to process and interpret visual information with unparalleled efficiency and effectiveness. These advanced architectures allow GPT-4 Vision to capture complex relationships and dependencies within images, leading to more nuanced and contextually rich interpretations.
Key Capabilities of GPT-4 Vision:
- Multi-modal Understanding: GPT-4 Vision excels in multi-modal understanding, meaning it can analyze both images and text simultaneously. This enables more comprehensive and contextually rich interpretations, as GPT-4 Vision can leverage both visual and textual cues to generate insights and responses.
- Fine-grained Recognition: GPT-4 Vision demonstrates remarkable prowess in fine-grained recognition, capable of identifying a wide range of objects, scenes, and concepts within images with high precision. Whether it's recognizing specific breeds of dogs, distinguishing between similar-looking objects, or identifying subtle visual cues, GPT-4 Vision excels in discerning fine-grained details.
- Adaptive Learning: GPT-4 Vision is highly adaptable to different tasks and domains through fine-tuning, a process that involves retraining the model on specific datasets or tasks. This adaptability makes GPT-4 Vision versatile and suitable for various image analysis applications, as it can quickly adapt to new contexts and requirements.
GPT-4 Vision represents a significant advancement in AI-driven image analysis, offering enhanced capabilities and performance that surpass its predecessors. With its ability to analyze images and text simultaneously, identify fine-grained details with precision, and adapt to different tasks and domains, GPT-4 Vision is poised to revolutionize the field of computer vision and shape the future of AI-powered image analysis.
Demo: Exploring GPT-Vision's Image Analysis on MobileGPT
Before we delve into the demonstration of GPT-Vision's image analysis capabilities on MobileGPT, let's first provide a brief overview of MobileGPT and its features.

Brief overview of MobileGPT and its features
MobileGPT is a personal AI assistant powered by the latest OpenAI technologies, including GPT-4, SDXL, and GPT-4 Vision. Accessible directly through WhatsApp, MobileGPT offers a wide range of functionalities, including coding assistance, image creation, document generation, educational support, and much more. Its integration of GPT-Vision enables users to perform image analysis tasks seamlessly within the messaging platform.
How MobileGPT Integrates GPT-Vision for Image Analysis
MobileGPT seamlessly integrates GPT-Vision into its AI capabilities, allowing users to perform image analysis tasks directly within the WhatsApp environment. Through a simple interface, users can upload images and query GPT-Vision for insights, descriptions, or answers related to the visual content.
The integration of GPT-Vision into MobileGPT enhances the platform's functionality, making it a versatile tool for a wide range of image-related tasks. Whether it's identifying objects in photos, generating captions for images, or extracting information from visual data, MobileGPT powered by GPT-Vision delivers powerful image analysis capabilities in a user-friendly and accessible manner.
Step-by-Step Demonstration of Using GPT-Vision on MobileGPT
In this section, we'll guide you through a step-by-step demonstration of leveraging GPT-Vision's powerful image analysis capabilities directly on MobileGPT. Follow along as we explore how to upload an image, query GPT-Vision for analysis, and engage in a conversation to extract valuable insights from visual content.
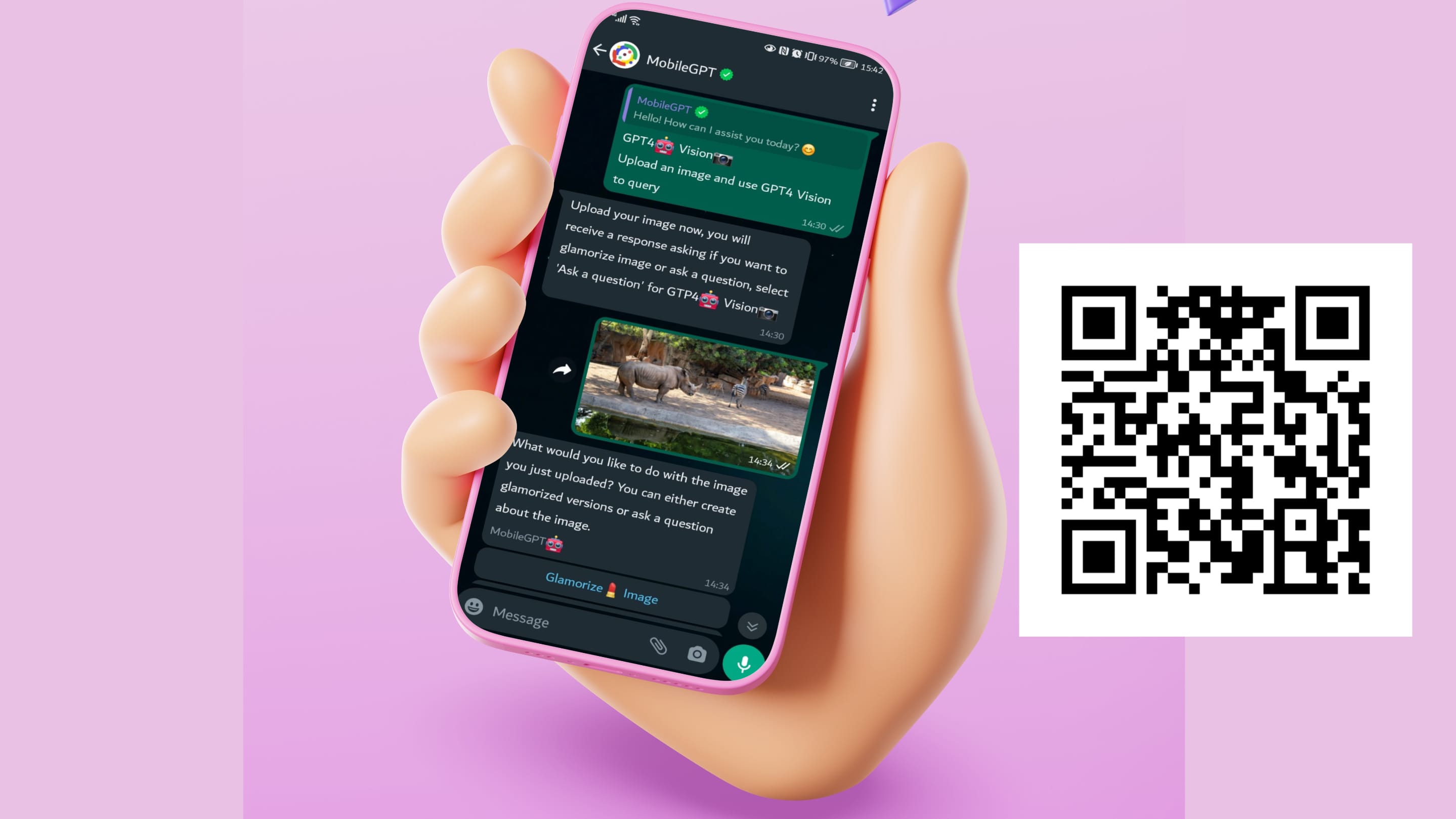
Step #1: Open WhatsApp and Initiate a Conversation with MobileGPT: Begin by launching WhatsApp on your device and initiating a conversation with MobileGPT. Simply type in MobileGPT's contact name or number and select it from your chat list to start the conversation.
Step #2:Access GPT4🤖 Vision📷 Feature: Once you're in the conversation with MobileGPT, navigate to the menu options. Look for the option labeled "GPT4🤖 Vision📷 - Upload an image and use GPT4 Vision to query." Select this option to activate the GPT-Vision feature within MobileGPT.
Step #3: Upload an Image: MobileGPT will prompt you to upload an image. Choose an image from your device's gallery that you'd like to analyze using GPT-Vision. After selecting the image, send it to MobileGPT.
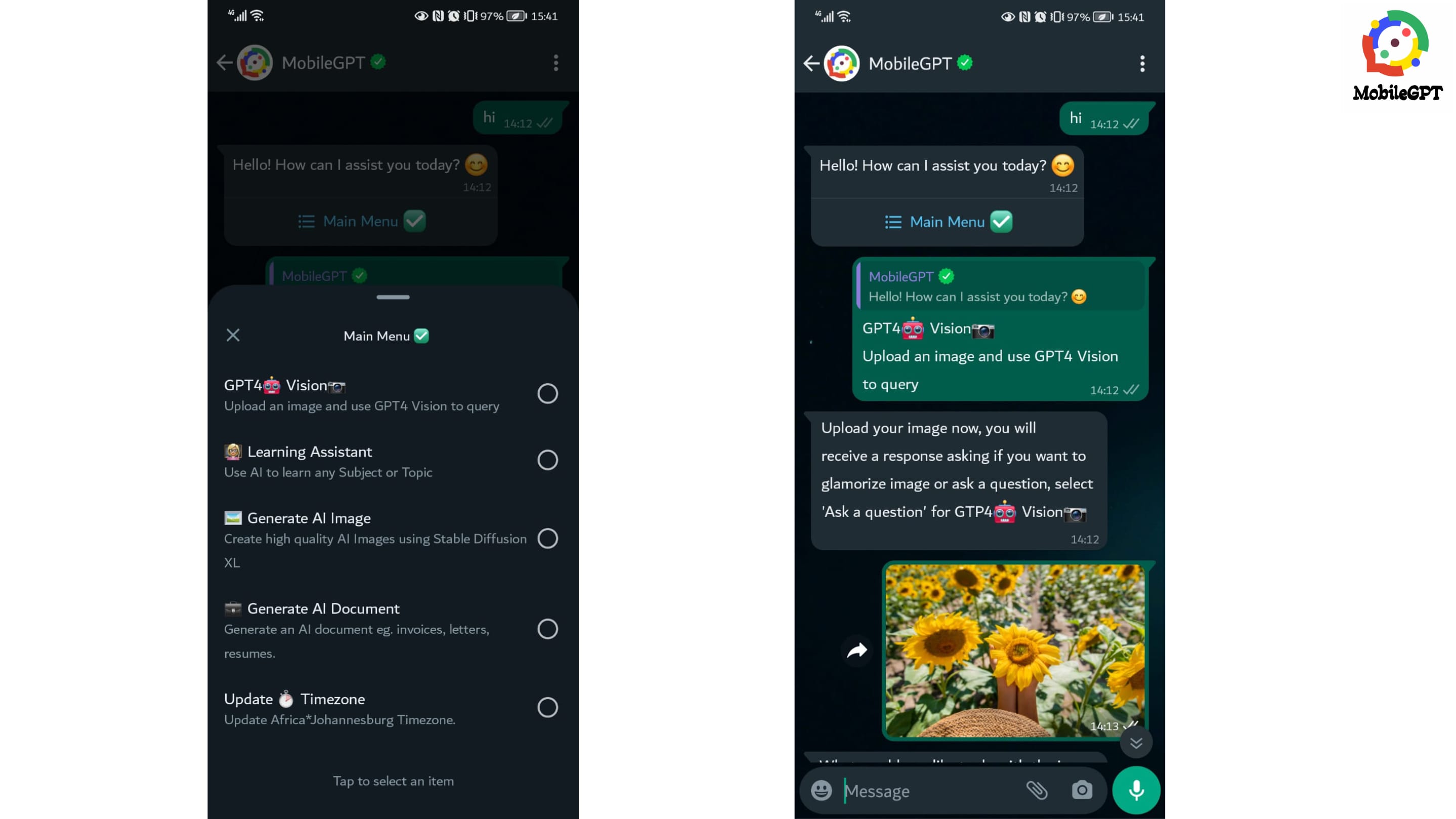
Step #4: Choose Query Type: After uploading the image, MobileGPT will respond with options for how you'd like to proceed. You'll typically be given the choice to "Glamorize image" or "Ask a question." Select "Ask a question" to engage GPT4🤖 Vision📷 in a query-based interaction.
Step #5: Ask Your Question: You can then ask a question related to the content of the uploaded image. Remember that your question can be 1 of the following as mentioned above:
- Object Recognition: Asking the AI to Identify and localize objects within images.
- Scene Understanding: Inferring the context and semantics of scenes depicted in images, such as indoor versus outdoor environments, urban versus rural landscapes, etc.
- Image Captioning: Prompting the AI to generate descriptive captions or summaries for images.
- Visual Question Answering: Requesting to AI to respond to a question posed about images.
For instance, if your image is of a sunflower, here are example prompt questions you can ask on MobileGPT about the sunflower:
- “Can you identify what is on the image”
- “Can you provide any information about the habitat or growing conditions?”
- “Was this picture taken indoor or outdoor”
- “Can you write a catchy caption for this image”
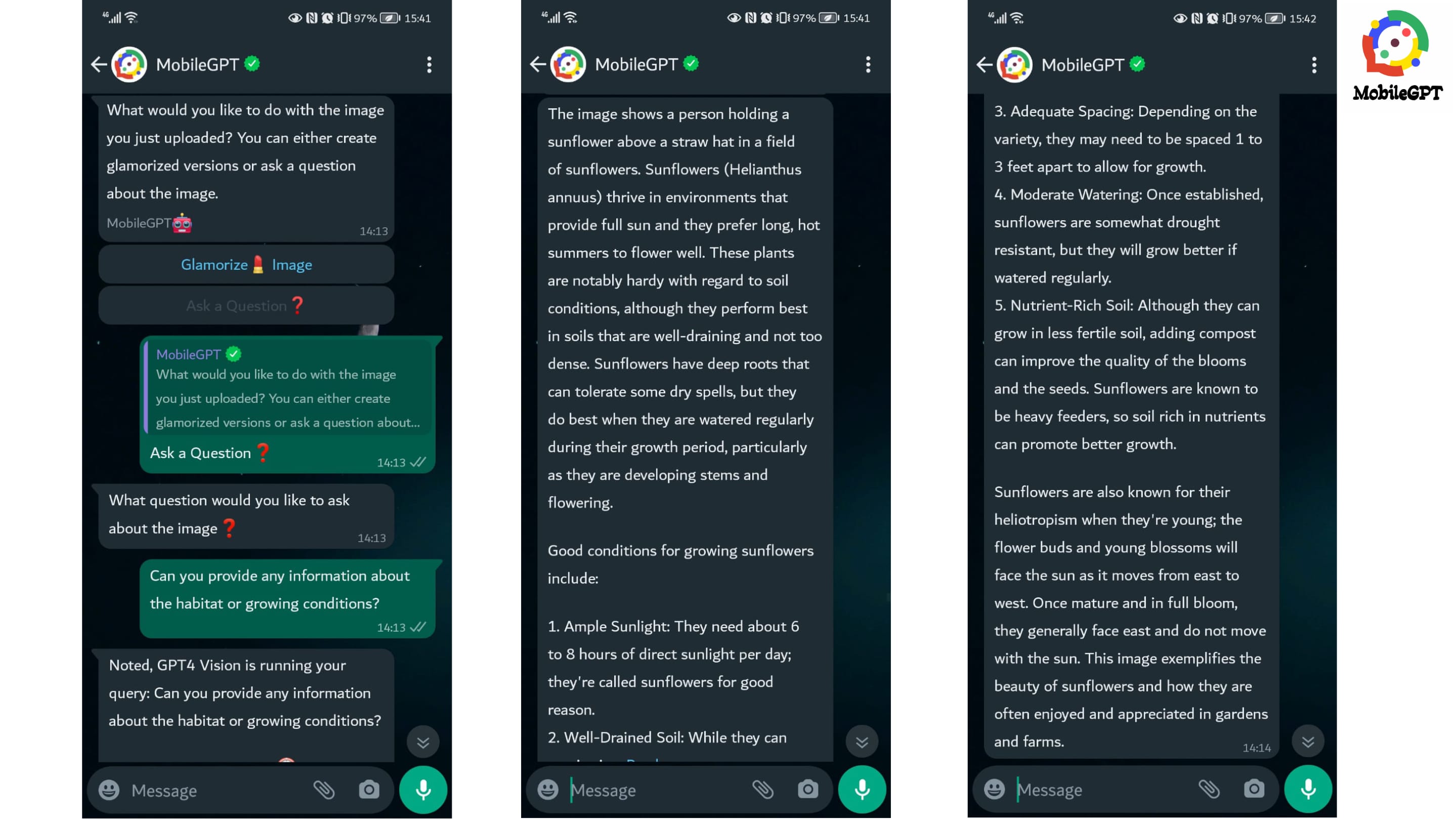
By leveraging the power of AI, users can quickly extract valuable information, identify key elements, and comprehend the context depicted in the image. This capability proves invaluable in various scenarios, from educational purposes to real-world applications. For instance, in educational settings, students can use GPT-4 Vision to deepen their understanding of complex concepts illustrated in images, enhancing their learning experience. In real-world applications, professionals can utilize this feature to streamline tasks such as image classification, object recognition, and scene understanding, thus improving productivity and decision-making. Overall, the ability to receive accurate and relevant responses based on uploaded images significantly enriches the user experience and underscores the transformative potential of AI-powered image analysis.
Tips for Using GPT Vision to the Fullest
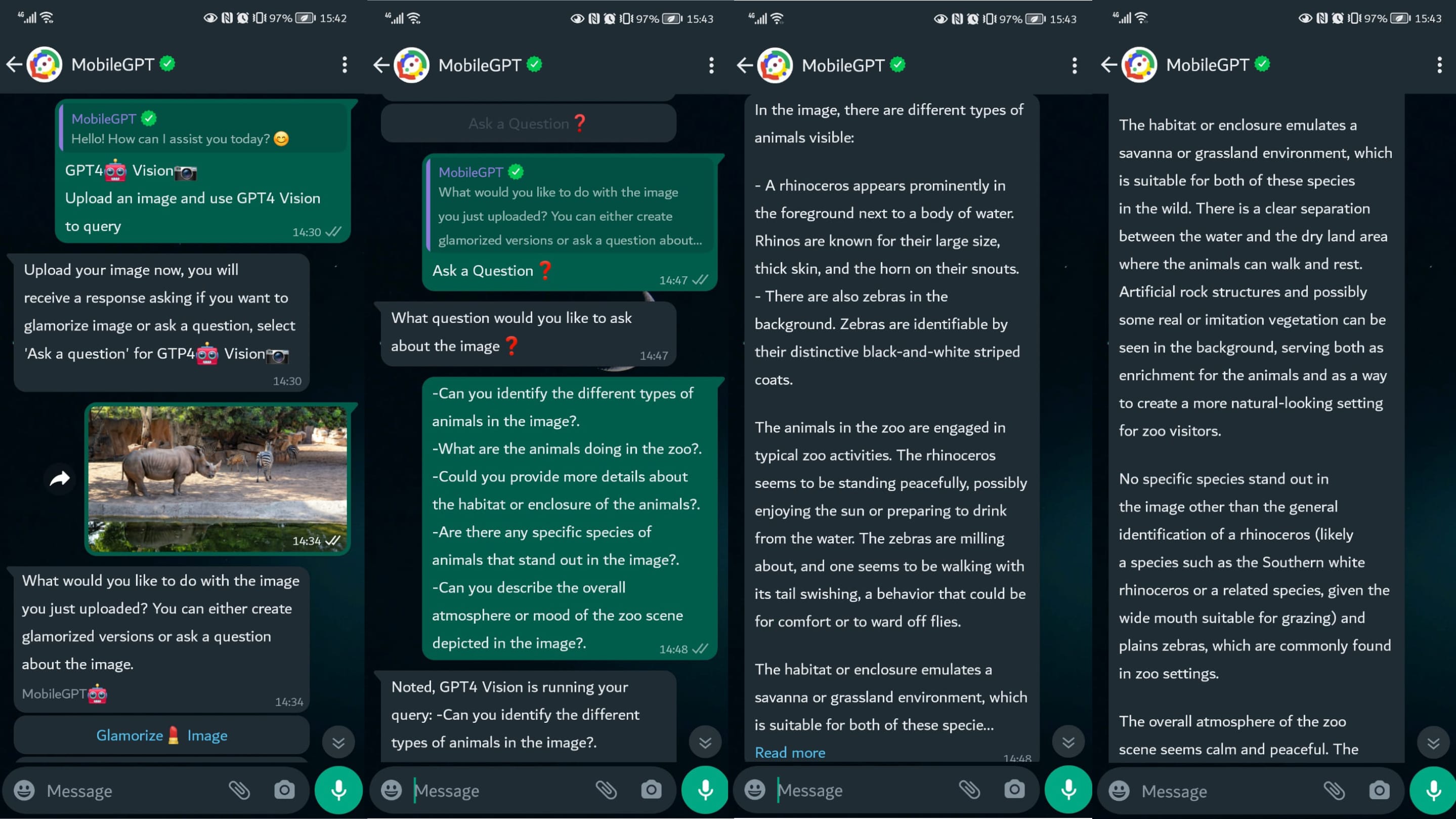
Compile a List of Questions: Since you only get to ask one question per image upload, it's best to compile a list of questions beforehand. By asking all your questions in a single text input, the AI will provide a comprehensive answer addressing each query you've posed. This approach ensures that you make the most out of each interaction with GPT Vision, maximizing the insights and information you receive.
Reupload the Picture for Additional Questions: Alternatively, if you find yourself needing more information or insights, you can simply reupload the same picture and ask another question. GPT Vision will analyze the image again and provide responses to your new inquiries. This allows for flexibility in exploring different aspects of the image or seeking clarification on specific details.
Experiment with Different Image Angles and Lighting: If you're not satisfied with the initial analysis or if GPT Vision struggles to provide accurate insights, try capturing the image from different angles or under different lighting conditions. This variation in perspectives can sometimes yield better results and improve the AI's understanding of the visual content.
Refine Your Queries: If you encounter any discrepancies or inconsistencies in the responses provided by GPT Vision, refine your queries and try asking the questions in a different way. Adjusting the phrasing or providing additional context can help GPT Vision better interpret your intentions and provide more accurate answers.
Keep Learning: Continuously explore and experiment with GPT Vision's capabilities to learn more about its strengths and limitations. As you gain familiarity with the AI's functionalities, you'll become better equipped to leverage its capabilities effectively in various situations.
By following these tips, you can leverage GPT Vision to its fullest potential, extracting valuable insights and information from visual content with efficiency and ease. Whether you're conducting research, seeking assistance, or satisfying your curiosity, these strategies ensure a fruitful and productive interaction with GPT Vision on MobileGPT.
Usecases for Image Analysis with GPT-4 Vision on MobileGPT
MobileGPT's integration with GPT-4 Vision opens up a myriad of use cases for image analysis, empowering users to gain insights and information from visual content with ease. Here are some scenarios where you can leverage GPT-4 Vision to enhance your daily life:
Culinary Assistance: Unsure what dish to prepare with the ingredients you have? Simply take a picture of your kitchen pantry or the ingredients you're working with, upload it to MobileGPT, and ask for recipe suggestions based on the items in the image.
Travel Planning: When exploring a new destination, capture images of landmarks, street signs, or menus written in a foreign language. MobileGPT's GPT-4 Vision can help translate text, identify landmarks, or provide contextual information about points of interest, enriching your travel experience.
Animal Rescue and Care: Encountered an unfamiliar animal in need of assistance? Snap a photo and ask MobileGPT for identification and care tips. GPT-4 Vision can recognize species, offer guidance on proper handling and care, and even suggest nearby animal rescue resources.
Academic Support: Struggling to understand a complex diagram or chart in your textbook or study materials? Upload the image to MobileGPT and ask for explanations or clarifications. GPT-4 Vision can provide detailed descriptions, break down visual concepts, and offer additional context to aid in your understanding.
Home Improvement Projects: Planning a home renovation or DIY project? Take photos of your space or inspiration images and consult MobileGPT for design recommendations, product suggestions, or troubleshooting advice. GPT-4 Vision can analyze interior layouts, identify decor styles, and provide expert insights to guide your project.
Fashion and Style Guidance: Unsure how to accessorize an outfit or incorporate a new fashion trend? Snap a photo of your clothing or accessories and ask MobileGPT for styling suggestions or fashion tips. GPT-4 Vision can recommend complementary pieces, offer outfit coordination advice, and help you stay on-trend.
Health and Wellness: Concerned about a skin condition or unfamiliar symptom? Take a photo and consult MobileGPT for preliminary insights or recommendations. GPT-4 Vision can identify common skin conditions, provide self-care tips, and suggest when to seek professional medical advice.
Simply take a picture, upload it to MobileGPT, and ask whatever you want to know about the image. With GPT-4 Vision's advanced image analysis capabilities, the possibilities are endless for leveraging visual content to enhance various aspects of your life.
Advantages of MobileGPT and GPT-Vision Integration
The integration of GPT-Vision into MobileGPT brings forth a multitude of benefits, elevating the user experience and expanding the realm of possibilities in mobile AI:
- Accessibility: By incorporating advanced AI capabilities directly into mobile devices, MobileGPT makes cutting-edge technology accessible to a wider audience. Users can harness the power of GPT-Vision's image analysis features from the palm of their hand, eliminating the need for specialized hardware or complex setups.
- Convenience: MobileGPT's integration with messaging platforms like WhatsApp enables users to perform image analysis tasks seamlessly within their everyday communication channels. This eliminates the need to switch between multiple apps or platforms, streamlining the workflow and enhancing overall efficiency.
- Versatility: The integration of GPT-Vision on MobileGPT opens up a myriad of use cases for image analysis. From identifying objects and scenes to generating captions and descriptions, GPT-Vision offers a versatile toolkit for various applications. Whether it's for educational, professional, or personal purposes, users can leverage GPT-Vision to enhance their understanding of visual content and extract valuable insights.
The integration of GPT-Vision into MobileGPT enhances accessibility, convenience, versatility, and personalization, empowering users to leverage advanced AI capabilities in a mobile-friendly and user-centric manner.
Final Thoughts on The Significance of GPT-Vision
GPT-Vision represents a significant milestone in the evolution of mobile AI, offering unparalleled capabilities for image analysis and understanding directly on our smartphones. Its integration into platforms like MobileGPT not only enhances accessibility and convenience but also paves the way for a new era of mobile computing where advanced AI capabilities are seamlessly woven into our everyday experiences. By harnessing the power of GPT-Vision, users can unlock a world of possibilities, from instant visual recognition to personalized insights tailored to their individual needs and preferences. As we continue to witness the transformative impact of GPT-Vision on mobile AI, it becomes increasingly clear that this technology will play a pivotal role in shaping the future of how we interact with and perceive the world around us.
Explore GPT-Vision on MobileGPT Today!
Experience firsthand the power and potential of AI-driven image analysis as you engage with GPT-4 Vision's capabilities to understand and interpret visual content with ease. Whether you're a student looking to enhance your learning experience, a professional seeking to streamline tasks, or simply curious about the possibilities of mobile AI, MobileGPT offers a gateway to a world of possibilities. click this link to add MobileGPT on your Whatsapp : https://wa.me/message/TRQTFU2TZDBGP1 or scan the QR CODE on the image below.
Take the first step today and unleash the full potential of GPT-Vision on MobileGPT. Your adventure awaits – dive in and witness the future of mobile AI firsthand!









